米Googleは12月16日(現地時間)、画像を入力することで画像を生成する新しい生成AIツール「Whisk」を発表しました。
画像生成AIって英語で細かなプロンプトをテキストで入力するのが一般的だけど、「Whisk」ではそれを画像を指定するだけで済むようになるのでプロンプトを考える手間がなくなって作業効率が上がりそうで期待してます!
目次
Whiskで何ができる?
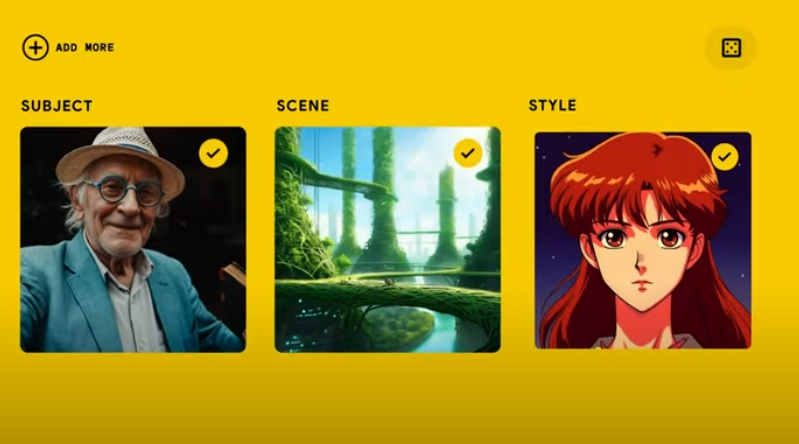
Whiskは、これまでの画像生成AIと違って、ユーザーが提供する複数の画像を組み合わせ、新たな画像を生成するAIツールです。
従来のテキストプロンプトによる生成とのおおきな違いは、テキストではなく画像を被写体、シーン、スタイルでそれぞれ用意することで新しい画像を作れるってところ。
テキストで細かな指示を出さずに画像を使って直感的に希望する画像を作成することができるのが大きな特徴です。
Whiskの仕組み
Whiskは、Googleの大規模言語モデル「Gemini」を活用し、ユーザーが入力した画像から詳細なキャプション(説明文)を自動生成します。
このキャプションを、最新の画像生成モデル「Imagen 3」に入力することで新たな画像を生成します。
入力画像の特徴を活かしつつ、新しい表現の画像を作成することができます。
Whiskの使い方
Whiskの使い方はGoogleがYoutubeで公開してるWhiskの紹介動画を見るのが一番わかりやすいです。